Девлог 6. Как мы провели лето, часть 2
Мы много времени потратили на пайплайн перевода, при этом у нас не проработанным остался вопрос: как повысить качество переводов? Мы видели разное — от сомнительных до совсем никудышних примеров — когда оценивали БЯМ по отдельности. Мы решили проверить простую гипотезу: если посчитаем перплексию для переведенного текста, используя небольшую обученную ЯМ, то тексты с большей перплексией и будут плохим переводом.
В качестве базовой ЯМ у нас была ai-forever/rugpt3small_based_on_gpt2, потому что с ней просто работать в плане запуска на имеющемся железе. Взяли эту модель, наши переводы, прогнали всё и получили перплексию. Быстро поняли, что лучше работать с логарифмированной перплексией, потому что для коротких текстов ее значения иногда долетают до Венеры. В итоге получилось у нас вот такое общее распределение и, далее, распределение, зависящее от длины текста.
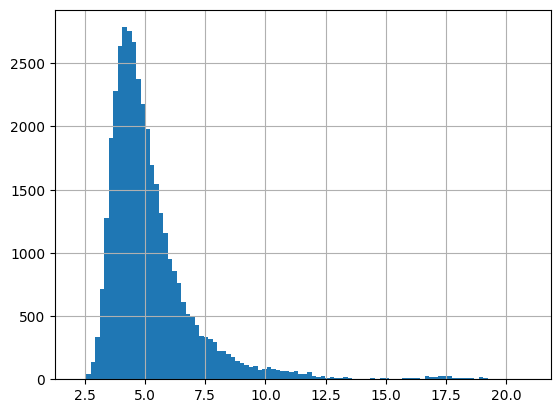
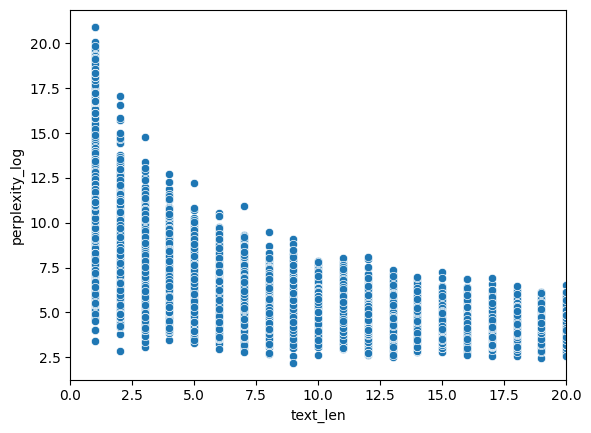
На общем распределении видно, что колокол смещен влево, а справа имеем длинный хвост. Такая картина дала надежду на правдоподность гипотезы. На втором распределении хорошо заметно, что размах перплексии изменяется от длины текста. Поскольку на совсем уж коротких текстах перплексия неадекватная, мы решили рассматривать только тексты длиннее пяти токенов. Мы решили в качестве границы брать четвертый квартиль: всё, что выше, мы считаем «плохим» переводом из-за большой перплексией. Чтобы учесть изменчивость размаха, мы распределеям значения длин в «корзинки» по децилям и считать квартили перплексии внутри каждой корзинки.
Вот такие переводы алгоритм посчитал «плохими»:
| text_eng | text_rus |
|---|---|
| But even when there were a lot of cases, there are some people on my floor that walked freely in and out many times in one day when it wasn’t safe for anyone. And I didn’t get that at all and that was when I was angry and anxious of their actions. | Но даже тогда, когда было много случаев, некоторые люди на моем этаже ходили свободно в и из дома много раз в день, когда это не было безопасно для никого. И я совсем не понимал этого, и тогда я был зол и тревожен из-за их действий. |
| am based on a quota. I am suppose to be able to move 10 pallets per hour. that’s almost impossible as it is a 1 million square foot warehouse. If i get a pallet on the west side and have to move it to the east side that takes 7-10 minutes even if your going dangerously fast. | работаю по квоте. Мне нужно перемещать 10 паллет в час. Это почти невозможно в складе площадью в 1 миллион квадратных футов. Если паллет находится на западной стороне, а его нужно перевести на восточную, это занимает 7-10 минут, даже если едешь с опасной скоростью. |
| I think I pretty much got everything I need from you- I just needed to vent I think. So we can stop talking now or whenever you have to leave | Я думаю, я получил все, что мне нужно от тебя - мне просто нужно было выговориться, думаю. Так что мы можем закончить разговор сейчас или когда тебе нужно уйти |
| She had a desire to do marine biology and I wanted to pursue law enforcement as a police officer, however due to my back injury that fell through recently. She would spend most of her time doing field work, which would require her to spend time out at sea. She was working in a nursing home at the time and was not a marine biologist. | Она хотела заниматься морской биологией, а я собирался посвятить себя службе в полиции, однако моя травма спины недавно все эти планы сорвала. Большую часть времени ей пришлось бы проводить в полевых условиях, что требует работы в море. В то время она работала в доме престарелых и не была морской биологом. |
| I can understand how you would feel like he doesn’t care about the strain it’s placed. Can I ask, are your daughters aware or involved in these rumors? This could make a difference in how you could respond. | Я понимаю, как ты можешь чувствовать, что он не заботится о твоем состоянии. Можно спросить, знают ли или участвуют ли твои дочери в этих слухах? Это может повлиять на то, как ты можешь отреагировать. |
А как нам убрать кавычки вокруг слова «плохих»? Надо провести стат. тест с людьми! Вот как мы его организовали:
- Отобрали случайным образом 25 переводов, которые мы определили как плохие.
- Отобрали случайным образом 25 переводов из всего объема данных.
- Удостоверились, что выборки не пересекаются.
- Смешали все примеры в одну кучу таким образом, чтобы потом их можно было разъединить по исходным группам.
- Разметили переводы по качеству по пятибалльной шкале.
- Разделили оценки в соответствии с двумя исходными группами.
- Полученные группы передали в функцию подсчета U-критерия Манна-Уитни
scipy.mannwhitneyu(perplexity_selected, random_selected).
Вот, что мы понимали под «качеством перевода»:
Оценивать качество перевода следует по их естественности с точки зрения русского языка. Чтобы было более понятно, вот список некоторых критериев, что мы под этим понимаем:
- Корректность грамматических конструкций (склонения, согласования в падежах и т.д.)
- Перевод должен точно передавать смысл оригинального текста
- Даже если смысл текста передан верно, текст не должен «резать глаз».
- Стиль перевода соответстует стилю оригинала.
- Фразы внутри переведенного текста должны быть связаны друг с другом логически и грамматически.
Разметчиков мы искали на Профи.ру. Критерий — либо образование переводчика, либо опыт работы таковым от 2 лет. Всего нашли трех людей. Итоговая оценка примера считалась как среднее от трех оценок. Иии… p-value=0.08. Это можно читать примерно так: «оно, может, даже работает, но лучше поискать что-нибудь понадежнее».
Кроме того, что надо найти плохие переводы, нам их нужно еще переделать. Все мы знаем, что если ваша БЯМ не справляется с задачей, нужно просто взять побольше. Поскольку у нас были уже нанятые люди, мы провели еще один стат. эксперимент: будет ли качество перевода лучше, если использовать модель большего размера? Чтобы это проверить, мы делали так:
- Отобрали 200 «плохих» текстов.
- Переводили с помощью мощной модели (в нашем случае gpt-4o).
- Просили человека сравнить, какой перевод лучше (или одинаково). Критерии качества см. выше.
- Результаты запихивали в биномиальный тест
binomtest(new_win, n=n, p=0.5, alternative='greater').
В итоге получили p-value=0.001. Правило «просто возьми модель побольше» работает.
Последнее, что мы по касательной затронули, это LLM-as-a-judge. Поскольку мы команда независимая, бережное отношение к ресурсам — наша абсолютная база. Проверка каждого придуманного алгоритма отборщика людьми с этим плохо соотносится. Было бы здорово с помощью БЯМ отбраковывать совсем плохие варианты.
Мы специально ничего не изучали в этой теме, просто решили провести еще один простой стат. тест на тех данных, что у нас есть: есть ли какие-то ассоциации между оценками разных БЯМ и оценками людей по качеству перевода? Тестировали мы вот этих товарищей:
- gpt-4o
- claude-sonnet-4
- gemini-2.5-flash
- qwen3-235b-a22b
- deepseek-chat-v3-0324
- llama-4-maverick
При этом тестировали в двух вариантах:
- стандартный — просили БЯМ поставить оценку от 1 до 5.
- упрощенный — просили БЯМ просто сказать плохой ли перевод или нет, а оценки людей мы схлопнули по схеме {1,2,3} — «плохой», {4,5} — «хороший».
Наличие ассоциации проверяли с помощью хи-квадрата. В результате получили вот такую таблицу
| Разметчик 1 | Разметчик 2 | Разметчик 3 | Среднее | |
|---|---|---|---|---|
| gpt-4o__15 | 1.000000 | 0.175658 | 0.001253 | 0.999996 |
| claude-sonnet-4__15 | 1.000000 | 0.387769 | 0.005886 | 1.000000 |
| gemini-2.5-flash__15 | 0.999996 | 0.118529 | 0.000040 | 0.999956 |
| qwen3-235b-a22b__15 | 0.999993 | 0.160640 | 0.000288 | 0.999976 |
| deepseek-chat-v3-0324__15 | 0.999997 | 0.101087 | 0.000426 | 0.999987 |
| llama-4-maverick__15 | 1.000000 | 0.214498 | 0.000771 | 0.999997 |
| gpt-4o__12 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| claude-sonnet-4__12 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| gemini-2.5-flash__12 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| qwen3-235b-a22b__12 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| deepseek-chat-v3-0324__12 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| llama-4-maverick__12 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
И тут странности. Ни одна БЯМ никак не соотносится с первым разметчиком, со вторым, конечно, не в ноль, но не стат. значимо, а вот с третьим уже соотносится. Средняя оценка и упрощенный вариант тоже не показывают от слова «ничего. Тут мы решили посчитать согласованность разметки качества и получили ни много ни мало -0.09 по Криппендорфу.

Получается, что и оценка отборщика недостоверна, раз у нас три человека, несмотря на критерии, судят о качестве перевода каждый по своим вайбам. Занимательно, что у БЯМ вайбы совпадают с одним из людей. Еще весьма вероятно, что достоверность теста с улучшением качества тоже получилась так себе по той же причине. В общем, нужно искать более надежный способ установления качества переводов. Будем думать.