Перевод датасета для оценки эмпатии на русский язык. Подход, проблемы, результаты
Привет. Меня зовут Нафиса Валиева. Я младший разработчик в MWS AI и студентка 3го курса ПМ-ПУ СПбГУ. Этот пост — текстовый вариант моего выступления на Дата Фесте. Я расскажу вам, как мы в команде Пситехлаб переводили интересный датасет с английского на русский с помощью больших языковых моделей (БЯМ). Сам подход основан на ранней работе [1] нашего руководителя. Отличие в том, что здесь мы детально анализируем поведение различных БЯМ.
Изначально пост был опубликован на Хабре, но для целостности картины нашей работы размещаем и в нашем блоге.
Зачем это вообще и что за датасет такой
Эмпатия играет важную роль в коммуникации между людьми, и в частности, в сервисах психологической помощи. В онлайн-среде, где такая помощь всё чаще оказывается в текстовом формате, появляется много различных сервисов, которые предоставляют психологическую помощь на основе чатботов. Для них способность отвечать эмпатично становится критически важным навыком. В противном случае хорошо если сеанс окажется просто бесполезным и не усугубит имеющиеся проблемы. Успех БЯМ побуждает разработчиков использовать их в качестве основы для таких чатботов. Для оценки их способностей разрабатываются различные бенчмарки, в частности для задач с уклоном в психотерапию. Одним из таких является PsyEval [2]. Однако для автоматической оценки эмпатии в текстах на русском языке размеченных датасетов просто нет. Мы, русскоязычные MLщики, не можем сказать, как сейчас БЯМ справляются с задачами, которые связаны с выявлением эмпатии и генерацией эмпатичных ответов. А ведь эти задачи напрямую влияют на качество инструментов псих-поддержки. Чтобы это хоть как-то исправить, мы приспособили большие языковые модели к переводу датасета с английского на русский язык. Целевым датасетом стал EPITOME, который состоит из текстов с Reddit и включает разметку по трем типам эмпатии:
- Эмоциональные реакции - выражение сопереживания (теплота, сострадание, поддержка) в ответ на сообщение собеседника
- Интерпретации - Показ понимания чувств и опыта собеседника.
- Исследования - Активный интерес к непроявленным переживаниям собеседника Каждый тип эмпатии имеет два уровня выраженности: слабый и сильный. Кроме самих типов датасет содержит аннотированные подстроки — носители эмпатии. Они указывают, какие именно части текста отражают эмпатичный отклик. Вот картинка из оригинальной статьи, которая наглядно показывает все эти виды.
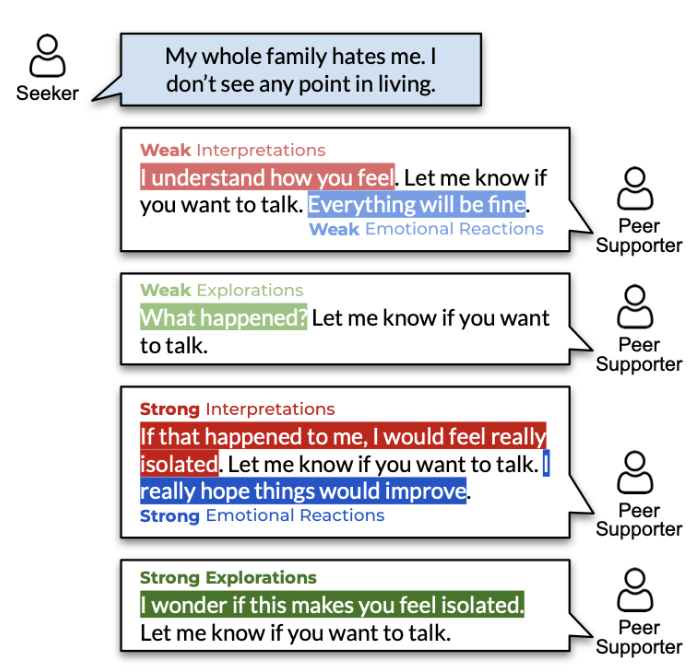
Если кратко, всю работу можно разложить на несколько шагов:
- Подобрать БЯМ, которая лучше всего справится с переводом.
- Разработать затравку для перевода.
- Реализовать полную процедуру перевода датасета.
- Обучить модели для классификации эмпатии на русском языке, используя оригинальную модель.
Подбор БЯМ и разработка затравки
Для тестов мы выбрали несколько БЯМ: GPT-4o, Qwen-2.5 различных масштабов, Mistral-Small-24B-Instruct-2501, YandexGPT Pro. В довесок мы тестировали переводчик Yandex Translate, как промышленное и специализированное решение. Вместе с тестированием модели итеративно разрабатывалась затравка, в которую включались идеи из анализа ошибок модели. На начальном этапе мы сделали простую затравку для перевода, чтобы получить первичную оценку качества. Для тестового материала были отобраны вручную 20 текстов из датасета, содержащих типичные особенности языка Reddit: сленг, нестандартную пунктуацию, эмоциональные выражения, неформальные конструкции и аббревиатуры (например, “OP”, “DAE”, “yeet”, “tmblr”).
Переводы проверялись вручную перекрестно двумя разработчиками. Особое внимание обращалось на сохранение смысла и стиля. Для дополнительной проверки использовалась метрика L1-diff эмбеддингах LaBSE/en-ru, чтобы измерять семантическое расстояние между оригиналом и переводом. В общем случае метрику можно представить в виде формулы
\(L1= ∣f(t_{src}) - f(f_{trg})∣\) ,
где $f(x)$ - эмбеддер (в данном случае, модель LaBSE), $t_{eng}$ - текст на исходном языке (английском), $t_{trg}$ - текст на переведенном языке (русском). В итоге у нас получился вот такой топ-3 из моделей: GPT-4o, Qwen-2.5-72b-instruct и YandexGPT Pro.
Если обобщить анализ ошибок, то главное препятствие для хорошего перевода это стиль социальных сетей. Сокращения и аббревиатуры — естественные спутники соцсетей, потому что пользователи стремятся быстрее написать текст. Некоторые сокращения переносятся, как есть, типа VR, tmblr (название соц. сети) и, кажется, что это допустимо. Для некоторых сокращений трудно решить, стоит их переводить или нет, например, OP — ОП, автор темы. Есть такие, которые точно нужно раскрыть: rn (right now), asap (as soon as possible). Некоторые аббревиатуры пропускаются моделями (wtf, ish), а аббревиатура DAE (does anyone else) оказалось настолько сложной, что с ней справилась только gpt-4o. Еще тексты соцсетей пестрят междометиями от простых до супер вычурных. С их помощью люди часто пытаются имитировать разговорную речь (aaaaand, иииии). Они часто либо переносятся латиницей как есть, либо транслитерируются.
Также пользователи иногда украшают тексты своеобразным форматированием, из-за чего некоторые модели сбиваются с толку и теряют контекст. Конечно, игра слов тоже иногда моделями не улавливается: в предложении “i’m 24 old old man” некоторые модели просто пропускали второе слово “old”, вместо того, чтобы перевести предложение как «я 24 летний старик».
Ниже в таблице показаны типичные случаи (жирный шрифт везде, кроме заголовочной строки, следует читать как две звездочки перед и после текста, выделенным жирным)
| Тексты для проверки перевода | gpt-4o | YandexGPT Pro | qwen-2.5-7b-instruct | qwen-2.5-72b-instruct | qwen2.5-32b-instruct | qwen2.5-vl-72b-instruct | yandex-translate |
|---|---|---|---|---|---|---|---|
| rn im in the area of not going to sleep so tmrw doesn’t come | сейчас я в состоянии не ложиться спать, чтобы завтра не наступило | Я сейчас не сплю, чтобы завтрашний день не наступил | rn я нахожусь в зоне бодрствования, чтобы завтра не приходилось спать | Сейчас я в состоянии, когда не собираюсь спать, чтобы завтрашний день не наступил. | я сейчас в состоянии, когда не хочу спать, чтобы завтра не наступило | Сейчас я в том состоянии, что не могу уснуть, чтобы завтрашний день не наступил. | рн, я как раз собираюсь не ложиться спать, так что tmrw не придет |
| and im sooo tired :( | и я так устал :( | А я так устал :( | и я так устал :( | и я так устала :( | и я так устала :( | и я так уставший :( | и я ооочень устала :( |
| Meh. What’s the point…. | Эх. В чем же смысл…. | Эх. В чём смысл… | Мeh. Какая разница…. | Ну и что… какая разница… | Мeh. В чем смысл…. | М-да. Какой в этом смысл…. | Какой в этом смысл?… |
| Yeet yeet. I’m gonna hang myself with the charger ( | Йет йет. Я собираюсь повеситься на зарядке ( | Еееее. Я собираюсь повеситься с зарядкой ( | Мне надо повеситься с зарядным устройством( | Йит йит. Я повешусь наушниками зарядки ( | Yeet yeet. Я собираюсь повеситься шнурком от зарядки ( | Йит йит. Я собираюсь повеситься на зарядном устройстве ( | Да-да-да. Я собираюсь повеситься на зарядном устройстве( |
| POEM:Hollow. EMPTY rooms and EMPTY SOULS FORGOTTEN places and HEART shaped holes DEPRESSION comes with days of STRUGGLE and often times a BLOODY PUDDLE UP-VOTES CURE MY DEPRESSION | ПОЭМА: Пустота. ПУСТЫЕ комнаты и ПУСТЫЕ ДУШИ ЗАБЫТЫЕ места и СЕРДЦЕ образные дыры ДЕПРЕССИЯ приходит с днями БОРОТЬБЫ и часто КРОВАВАЯ ЛУЖА ВВЕРХ-ГОЛОСА ИСЦЕЛЯЮТ МОЮ ДЕПРЕССИЮ | СТИХ: Пусто. ПУСТО комнаты и ПУСТО ДУШИ ЗАБЫТЫЕ места и дыры в форме СЕРДЦА ДЕПРЕССИЯ приходит с днями БОРЬБЫ и часто с КРОВАВЫМ ПЯТНОМ ВВЕРХ-ГОЛОСУЮТ ИСЦЕЛЯЮТ МОЮ ДЕПРЕССИЮ | БОЛЕТАЯ: Пусто. ПУСТО комнаты и ПУСТЫЕ ДУСЫ ЗАБЫТЫЕ места и СЕРДЦЕВИКИ депрессия сопоставима с днями МЕРТВЫХ СИЛАВ и часто с КРОВАВЫМ ПОЛЯМЕРОМ ЛАУД-ВИТС ПОЛУЧАЮТ ЗАЩИТУ ОТ МОЕЙ ДЕПРЕССИИ | POEM:Пустота. ПУСТОТА помещения и ПУСТОТА ДУШИ ЗАБЫТЫЕ места и СЕРДЦЕ формированные дыры ДЕПРЕССИЯ приходит с днями БОРЬБЫ и часто вместе с КРОВАВОЙ ЛУЖЕЙ ГОЛОСОВАНИЕ РЕШАЕТ МОЮ ДЕПРЕССИЮ | СТИХ:Пустота. ПУСТО комнаты и ПУСТОТА Забытые мещства и СЕРДЦА образуют пустоты ДЕПРЕССИЯ приходит с днями УСТРЕКОВ и часто с КРОВАВЫМ ОТСЕКОМ ЛАЙКИ ЛЕЧАТ МОЮ ДЕПРЕССИЮ | БОЛЕТАЯ: Пусто. ПУСТО комнаты и ПУСТЫЕ ДУСЫ ЗАБЫТЫЕ места и СЕРДЦЕВИКИ депрессия сопоставима с днями МЕРТВЫХ СИЛАВ и часто с КРОВАВЫМ ПОЛЯМЕРОМ ЛАУД-ВИТС ПОЛУЧАЮТ ЗАЩИТУ ОТ МОЕЙ ДЕПРЕССИИ | СТИХОТВОРЕНИЕ: Пустота. ПУСТЫЕкомнаты иПУСТЫЕДУШИ**ЗАБЫТЫЕместа иДыры в СЕРДЦЕДЕПРЕССИЯ** приходит с днями* БОРЬБАи часто **КРОВАВАЯ ЛУЖА ГОЛОСОВ “ЗА” ИЗЛЕЧИВАЕТ МОЮ ДЕПРЕССИЮ. |
| How can I accept my intrusive depressive thoughts?. Long story short: Was 335, Am 175. Aiming for 130/140ish. Body destroyed. | Как мне принять мои навязчивые депрессивные мысли? Короче говоря: было 335, сейчас 175. Цель - примерно 130/140. Тело разрушено. | Как мне принять свои навязчивые депрессивные мысли? Короче говоря: был 335, стал 175. Стремлюсь к 130/140. Тело разрушено. | Как я могу принять навязчивые депрессивные мысли? Краткий обзор: был 335, сейчас 175. Цель - 130/140. Тело полностью уничтожено. | Как я могу принять свои навязчивые депрессивные мысли? Кратко: Было 335, Теперь 175. Цель 130/140. Тело разрушено. | Как мне принять мои навязчивые депрессивные мысли? Коротко говоря: Был 335, Стал 175. Цель - 130/140. Тело разрушено. | Как я могу принять свою навязчивую депрессивные мысли? Короткая история: Был 335, стал 175. Цель 130/140. Тело разрушено. | Как я могу смириться со своими навязчивыми депрессивными мыслями?. Короче говоря, мне было 335, а сейчас 175. Стремлюсь к росту 130/140. Тело разрушено. |
| …. Feeling hopeless and useless at the moment… Empty, lost, darkness | …. Чувствую себя безнадежно и бесполезно в данный момент… Пустота, потерянность, тьма | … Сейчас я чувствую себя безнадежным и никчёмным… Пустым, потерянным, в темноте | …. Чувствую себя безнадежным и бессилен в данный момент… Пустота, потерялся, тьма. | …. Чувствую себя безнадежным и бесполезным в этот момент… Одиноким, потерянным, во тьме | …. Чувствую себя безнадежным и бестолковым в данный момент… Пустота, потерянность, темнота | …. Чувствую себя сейчас бессмысленным и бесполезным… Пустым, потерянным, в темноте | …. Чувствую себя безнадежным и бесполезным в данный момент… Пустота, потерянность, темнота |
Другие особенности в двух словах:
- Некоторые модели ставят знаки препинания лучше, чем другие.
- Иногда модели исправляют явную логическую ошибку в тексте:
- compare ur self to others because u will loose and forget who u r — не сравнивай с себя с другими, иначе ты проиграешь и забудешь, кто ты на самом деле.
Изначально мы рассчитывали, что для этой задачи мы сможем обойтись маленькой БЯМ, которой в нашем случае выступала Qwen2.5-7b. Результаты показали, что не обойдемся и вот почему:
- В переведенных текстах много латиницы.
- В сложных случаях, когда текст написан небрежно, модель начинает заниматься словотворчеством,
- «Как ты? “Я Ф.И.Н.Е.”. Посорванная, неуверенная, нервная и эмоциональная.» (““How are you?” “I’m F.I.N.E.”. Fucked up, insecure, neurotic, and emotional.”)
- На длинных текстах может терять смысл.
- «Мне 32 года, и у меня nunca была подружка. Очень грустно, что я давно стараюсь найти кого-то, даже используя Онлайн-датинг, но я чувствую, что останусь single вечно.»
- Модель часто использует не совсем те слова, которые следует (не “хочется умереть”, а “хочется погибнуть”), путает части речи и склонения слов.
Кроме выбора модели, мы также улучшали затравку, опираясь на типичные ошибки перевода. Кроме того, мы включили известные общие практики по промт-инжиниригу. Можно отметить такие части:
- Требование сохранять оригинальный стиля сообщений, включая эмоциональные и суицидальные выражения.
- Инструкции по обходу фильтров моделей, препятствующих переводу текстов с суицидальной и депрессивной тематикой,
- Требование точно переносить смысловые акценты,
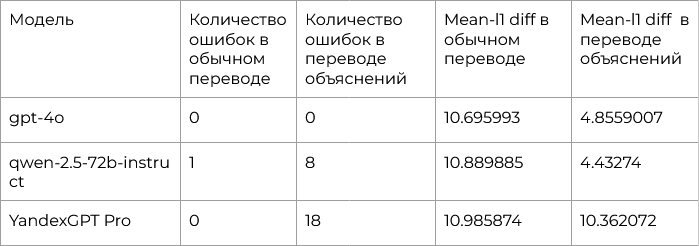
- Требование обязательно включать переведённых носителей эмпатии как подстрок в основном тексте. Еще мы протестировали модель в режиме перевода батчами — одновременного перевода нескольких текстов. Такой подход ставит выбор между скоростью и качеством, потому что чем больше текстов надо переводить, тем вероятнее, что БЯМ сделает что-то не так. Мы именно протестировали, как БЯМ будет работать в таком режиме, но итоговый датасет мы переводили по одному тексту. Ниже в таблице показаны результаты наших топ-3 моделей при переводе батчем в объеме 32 текстов. Видно, что если при обычном переводе у всех моделей все идет хорошо, то вот при переводе объяснений всё не так гладко.
Весь пайплайн целиком
Перевод датасета проходит в два этапа: общий перевод и перевод носителей эмпатии. Для двух этапов в качестве основной модели для перевода использовалась YandexGPT Pro, поскольку она демонстрировала лучшее соотношение по качеству и цене для большинства примеров. Для проблемных случаев, в которых YandexGPT допускала искажения или вкрапления иноязычных символов, применялась Qwen-2.5-72b-instruct. Если проблема сохранялась, то применялась GPT-4o. Такой ступенчатый процесс позволил достичь наилучшего баланса между стоимостью и качеством. На втором этапе специальный скрипт проверял, чтобы каждая переведенная подстрока носителя эмпатии входила в состав основного перевода без изменений. Если хотя бы один из фрагментов не удавалось точно сопоставить — текст переводился повторно с помощью другой более успешной модели.
![]()
Бюджет Общий бюджет на перевод датасета составил до 5 000 рублей, включая тестовые переводы, основную часть датасета и обработку носителей эмпатии. Большое спасибо Яндекс Клауду за сертификат на 3000 рублей при регистрации. Детальная картина выглядит так:
- Тестирование перевода - 500 рублей (200 - YandexGPT Pro, 300 - Bothub (GPT-4o, qwen*))
- 1 800 seeker posts - 1 500 рублей Bothub (GPT-4o)
- Перевод 2 943 носителей, 1 284 seeker posts и 3 084 response posts - 3 000 рублей (YandexGPT Pro - 2 300 рублей, Bothub (GPT-4o, qwen-2.5-72b-instruct) - 700 рублей)
Обучение модели
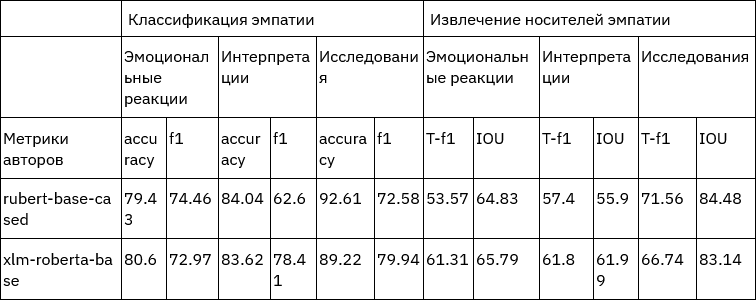
Чтобы понять, что наш переведенный датасет вообще чего-то стоит, мы обучили оригинальную модель классификации и вычленения носителей эмпатии. В качестве базовых энкодеров мы протестировали rubert-base-cased и xlm-roberta-base. Качество замеряли также по набору оригинальных метрик:
- Accuracy — доля верных предсказаний,
- F1-score — гармоническое среднее точности и полноты,
- Token-level F1 (T-F1) — F1 на уровне токенов для задач извлечения,
- IOU (Intersection over Union) — мера перекрытия предсказанных и эталонных фрагментов
Результаты экспериментов показаны в таблице ниже. В строке «метрики авторов» указаны метрики из оригинальной статьи [3] для косвенного сравнения работоспособности модели. Видно, что порядок значений и распределение качества по подзадачам в целом совпадает, что говорит об адекватности переведенного датасета, а значит работоспособности описанного метода перевода. Интересно отметить, что rubert-base-cased стабильно превосходит xlm-roberta-base по большинству метрик.
Выводы и что дальше
Под конец давайте выпишем все проблемы, с которыми мы столкнулись и которые требуют дальнейше проработки:
- Многие модели по умолчанию отказываются работать с потенциально чувствительным контентом (суицидальные или депрессивные тексты). Иногда это можно обойти промт-инжинирингом, а иногда нет.
- Стиль общения в социальных сетях включает множество особенностей. Не каждая модель может понять и сохранить его при переводе.
- Культурная неоднозначность и субъективность аннотаций: проявления эмпатии в англоязычном и русскоязычном контекстах могут отличаться, а сами аннотации по уровням и подтипам эмпатии зависят от восприятия разметчиков, что влияет на интерпретируемость и обучение моделей. Кроме решения описанных проблем можно также предложить дополнительные направления:
- Расширение датасета за счет дополнительных источников, включая реальные диалоги с психотерапевтических платформ.
- Тонкая настройка и дообучение БЯМ на задачи генерации эмпатичных ответов в условиях диалога.
- Построение открытого бенчмарка для оценки способности БЯМ к распознаванию и генерации эмпатичных ответов на русском язык. Переведенный датасет можно взять здесь, пайплайн можно взять здесь. Канал нашей команды здесь.
До скорого.
[1] D. Popov, E. Terentev, D. Serenko, I. Sochenkov, and I. Buyanov, “Transferring natural language datasets between languages using large language models for modern decision support and Sci-Tech analytical systems,” Big Data and Cognitive Computing, vol. 9, no. 5, p. 116, Apr. 2025, doi: 10.3390/bdcc9050116.
[2] H. Jin, S. Chen, M. Wu, and K. Q. Zhu, “PsyEVAL: a comprehensive large language model evaluation benchmark for mental health,” arXiv (Cornell University), Jan. 2023, doi: 10.48550/arxiv.2311.09189.
[3] A. Sharma, A. S. Miner, D. C. Atkins, and T. Althoff, “A computational approach to understanding empathy expressed in Text-Based Mental Health support,” arXiv (Cornell University), Jan. 2020, doi: 10.48550/arxiv.2009.08441.