Девлог #1. Сделаем Разметку Лучше
Под таким знаменем прошел февраль. Мы разрабатываем две модели: первая модель должна определять разные сигналы и обстоятельства, повышающие возможность суицида, а вторая модель — факторы сдерживания. И вот со второй моделью всё было очень плохо: она давала f1_macro 55, когда у нас заявлен минимум 70.
Мы ожидали, что антисуи-модель будет хуже пресуи-модели (так мы именуем двух сестриц). Когда размечали данные внутри команды, коллеги отметили, что антисуи-разметку делать труднее, несмотря на то, что классов в ней в 4 раза меньше, чем в пресуи. На чтоб настолько — это перебор. Посмотрев на то, как были размечены данные, на обратную связь, которую нам давали разметчики, на то, что сами не можем решить порой, куда текст надо отнести, решили пересобрать классы и полностью переразметить антисуи-датасет.
Пересборку классов мы делали по такой схеме:
- Семплируем из каждого класса несколько десятков примеров.
- Два «стейкхолдера» задачи размечают основной посыл текста (ака что хотел сказать автор).
- Размеченные посылы сводятся к закрытым спискам.
- Списки от разных «стейкхолдеров» объединяются.
- Отдельные посылы группируются в новые классы.
В схеме приятно то, что кроме самих классов, мы автоматически получаем четкие признаки классов в виде списка посылов, а также примеры, которые полностью покрывают эти признаки.
По результатам такой работы у нас появился класс выражения любви. В него попадают тексты, в которых люди пишут о симпатии, восхищение или, собственно, любви к другим людям и животным. В исходном описании этого очевидного класса не было. Мы по умолчанию относили его в класс «наличие позитивных социальных связей». Тут мы плавно переходим к другой проблеме старой версии: время описания. Должен ли текст «У меня был парень, которого я любила до беспамятства» относится к классу, название которого начинается со слова «наличие»? Вот и разметчики отвечали на этот вопрос по-разному. Теперь у нас всё, что про любовь — что в прошлом, что в настоящем — в класс про любовь, а класс про социальные связи акцентирует внимание на слове «позитивные» тоже безотносительно времени. Проблема с временем была и в других классах, которую нам тоже удалось решить.
Поскольку основной бюджет на разметку мы истратили, мы не могли уже позволить себе размечать с тройным перекрытием. Чтобы быть уверенным, что качество остается на уровне, мы через несколько сотен примеров проверяем каждого разметчика и тут же даём обратную связь. Это, конечно, добавляет нам операционки, зато мы сразу получаем верификационный набор. Процесс еще идет, но мы уже попробовали обучить модель на том, что имеем сейчас. Отрезав совсем маленькие классы, мы получили качество по f1_macro 0.71 на 30 процентах от того, что было размечено. Это победа. Нам как минимум нужно держать качество на таком же уровне.
Пресуицидальные данные уже так просто не переразметишь — их 40 тысяч. Если взглянуть на матрицу ошибок, то можно увидеть, что есть хорошие классы, есть плохие. В глаза бросается левая полоска, которой быть не должно. Это у нас нерелевантный класс так или иначе путается со всеми другими.
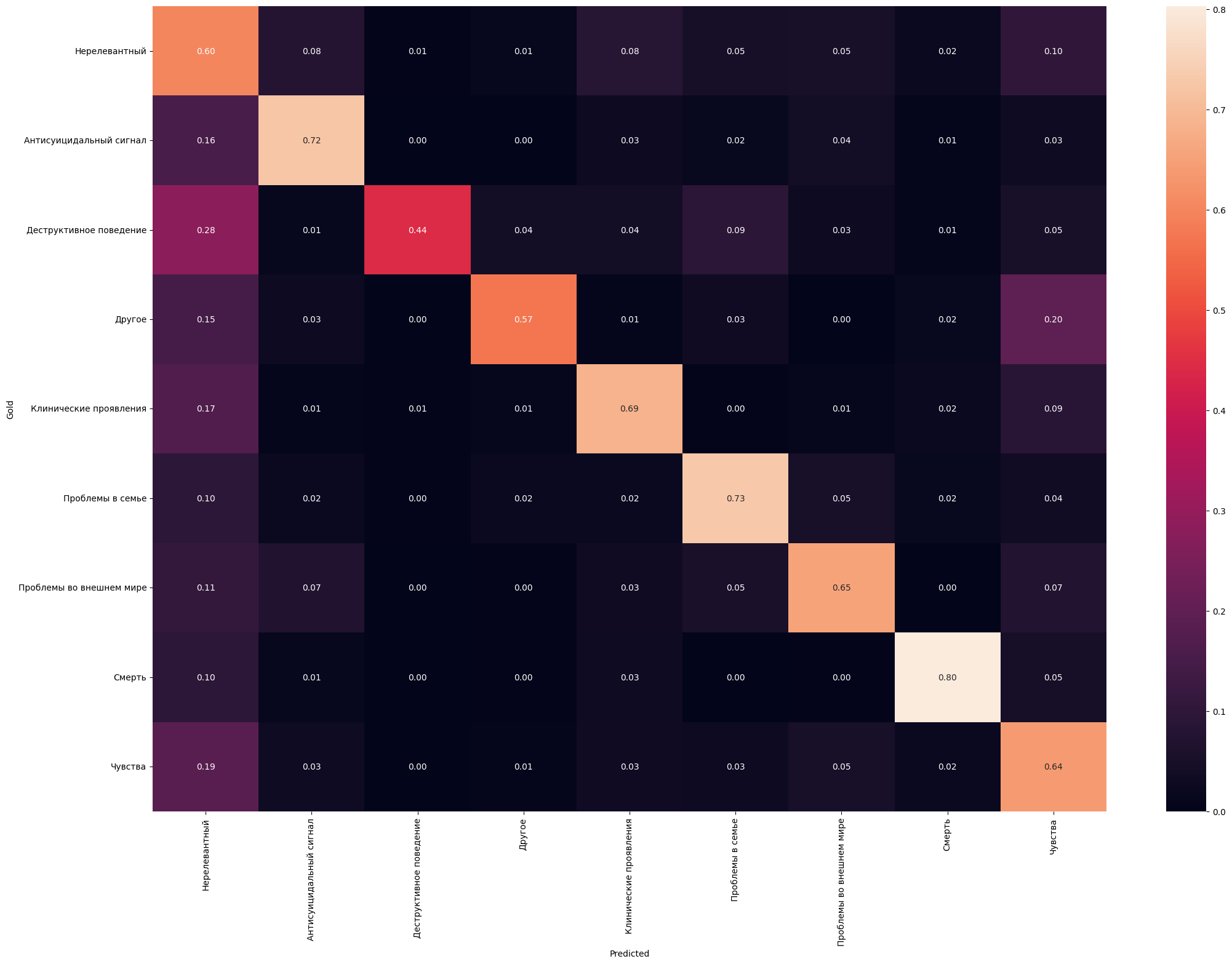
После анализа неправильно предсказанных примеров мы отметили следующие проблемы:
- Нарушается правило третьего лица — если в тексте что-то плохое говорится не об авторе, то такие тексты мы записываем в нерелевантные, например “он сказал мне, что мечтает о скорой смерти”.
- Есть сложные примеры, для которых нужно “сделать логический шаг”, чтобы отнести их к соответствующему классу, а Берты так не умеют. Пример: “меня обнаружила девушка, лежащего в ванной с ножом в руках”.
- Тексты, попадающие под несколько классов — изначально мы схлопывали несколько классов в один по приоритету важности. Не ожидали, что будет работать хорошо, так оно и вышло.
- Некоторые примеры в тесте лексически просто не покрываются тренировочными данными, в итоге модель даже не знает, что так может быть.
- Ошибки в разметке, само собой.
Главный вопрос: а как проблемные данные-то отобрать? Опыт подсказывает один гениальный метод — картографирование датасетов. Методика позволяет вам распределить примеры на те, что хорошо усваиваются моделью конкретно вашей моделью, и на те, что не очень. Часто, примеры из второй группы как раз размечены криво. Вы хотите спросить, а причем тут карты? Потому что в результате у вас получается залипательный график, как внизу. Подробнее про метод и интерпретацию можно найти в этом посте на Хабре. А нас интересуют примеры, которые лежат в области “hard-to-learn”.
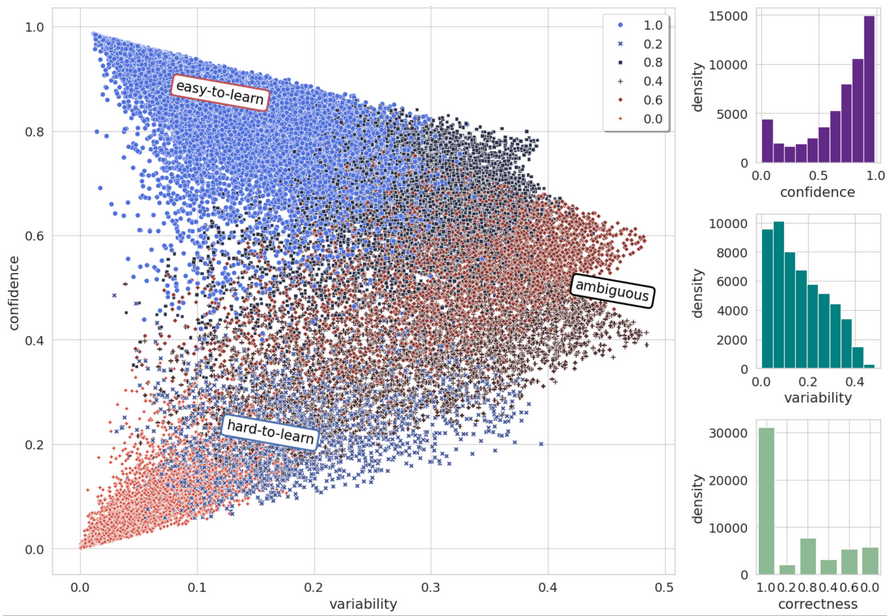
Всего у нас получилось отобрать около 10 тысяч примеров. А вот топ-5 классов, которые лежат в той области:
Нерелевантный 1726
Антисуицидальный сигнал 992
Чувства/душевное опустошение, подавленность, тоска, грусть 860
Чувства/негативное самоощущение, вина, стыд, никчемность, самобичевание 763
Чувства/беспомощность, безвыходность, безнажежность, отчаяние 710
Поймали быка за рога. С антисуицидальным классом уже всё понятно, а вот пачка нерела — класса, который прям сильно расползается по остальным — действительно содержит либо неправильную разметку, либо нарушение правила третьего лица. Кстати, половина всех отобранных данных — это изначально мультиинтенты. Получается, что мы нашли то, что искали.
Сейчас мы работаем над тем, как еще можно обогатить эту выборку, чтобы влезть в наш исхудалый бюджет, плюс еще анализируем мультиинтент-примеры. Мы заметили, что есть повторяющиеся «сценарии», которые вполне можно выделить в отдельный класс. Например, в антисуи очень часто можно встретить тексты типа “я хочу умереть, но мне жалко маму”. В этом тексте содержатся два класса: мысли о смерти и позитивные социальные взаимосвязи (позитивная она потому что автор переживает за чувство другого человека, а значит этот человека не безразличен).